If you have a cat, you know that sometimes his instincts push it to eat green eatable-looking plants, whatever they are, and whatever the consequences may be.
Spoiler: most of the time, it will require manual cleanup by the humans that happen to inhabit the same place.
It happens such a cat is living at my place.
And the Cat is often tempted by a plant which is not good for him.
So a solution had to be thought, as having a cat rejecting his stomach contents while you are in a middle of a meeting as you are working remotly from home is often a distractor not only for you but for your colleagues.
As a bonus, the device we would end up building could be used to prevent the cat from accessing other forbidden parts of the house, for example tables, kitchen hot plate..
End result
Let’s break the habits of this blog, and show end results first!
Recognize the Cat
Idea is to use tensorflow/OpenCV on a cheap raspberry 3B+ to detect the cat.
After some tests, it appeared this model gave many false positives for categories others than cat, in particular « person » detection.
However, no false positives seen for the cat category, and some false negatives.
So that’s good enough to start plugging that detector to real-life world.
The link to the real world
After having thought of putting some electronics/motor in a cheap, plastic water spray I already owned, similar to that:
I realised implementation would take time, multiple 3d-printing iterations (I have not seen any prior art in thingiverse) and my 3dprinter requiring maintainance + having little time to dedicate to that presently, I decided to go for another solution.
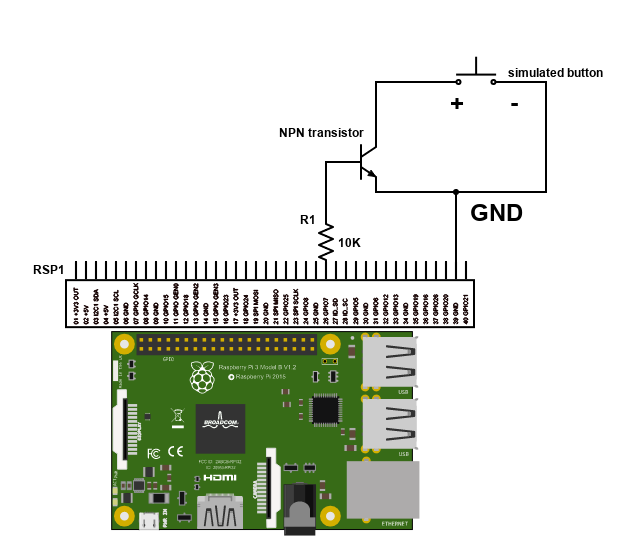
Which – I imagined- would be easy to hack so that it could be controlled by the raspberry GPIOs rather than the original push button.
Step 1: Open the spray
Be careful with screws hidden below the plastic adhesive on the sides of the spray.
Then just use common sense to remove parts carefully, you should end up with that:
Parts we will put back together once we are done
As you can see, one can easily see the button switch located in a dedicated PCB, link to the main logic PCB with black and red wires. Both wires are shortcut when button is pressed.
So we need to simulate that shortcut.
Extend wires
First, let’s get rid of the button part, to this end you can just unsolder the two wires. This option is preferable to cutting, as wires will be longer, which will be easier to handle what comes next.
Button PCB has been unsolderedWe extend wires with new ones, and we protect conductive parts with heat-shrinkable sleeve
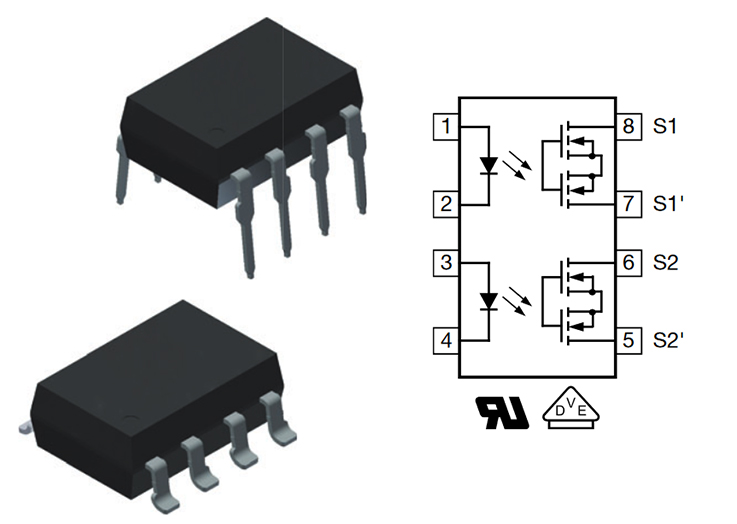
How to simulate shortcut with the Raspberry
So several options were considered:
using a relay
+ : easy to put in place, very good isolation
– : noisy when it operates, overkill for our application (very low current/voltage), not the least expensive, takes place (it’s big)
using optocouplers
+ : very strong decoupling/isolation, quiet
– : not the least expensive,
using transistor
– : not the best isolation, but works fine in our case as we play with small voltage (the voltage difference between the 2 pins to shortcut from the spray is <5v
+: very cheap, quiet, easy to put in place, small form factor
And Now for Something Completely Different, let’s move away from concrete stuff and bite a bit of Machine Learning abstraction (which – who knows – we may plug in a “real life” apparatus) in the good company of indisputably the best story tellers of the 20th century, Carl Barks and Don Rosa.
For the unlucky ones who don’t know them, or rather the lucky ones who don’t know them (who can’t worship them (yet)), Carl Barks and Don Rosa are respectively the creator of the wide Duck world and the guy who refreshed the “franchise”.
They both share a tender respect for the both mild and deep universe they created.
A dive into the awe of an anthropomorphic universe, where adventures always mean discoveries, where gold is often but not always at stake, sometimes Goldie is to be found.
Goldie, an ambiguous acquaintance from Scrooge’s youth
As for Goldie, characters are often not what they appear, Donald Duck despite his uncontrollable anger happens to be the best uncle for his three nephews, most cherished treasures of the stingly Scrooge McDuck are clearly not worth a lot of dollars or the lucky-lookingly Gladstone Glander does not live such a wonderful life, really.
Clearly, that’s an invitation to see characters behind appearances.
Ok, then what?
Now you may wonder, why such hommage in this blog?
Well, your devoted blog author (myself) being (as you guessed) an idolatrous of this universe, I thought this could be an entertaining opportunity to hands-on Tensorflow, a very accessible neural network framework.
Long term goal is to apply training/inference to real-world devices with sensors, and actuators.
Short term goal, depicted in this article, will be one of the simplest activity offered out-of-the-box by such frameworks (many coexist) : classification.
How? Well, Carl Barks and Don Rosa have very different drawing styles, obvious to the passionate reader.
So I was wondering whether a cold, (a priori) unpassionate convolutional neural net could figure that out.
Why Tensorflow?
First, let me restate that this blog is about experiments done out of curiosity, and clearly not written by an expert in the fields and techniques involved.
That being said, your servant (myself) happened to briefly look at the state-of-the-art of neural networks… at the end of last century (the nineties).
A time when perceptrons and Hopfield topologies were ruling keywords under the then-more-restricted neural network realm. A time those under 20 years old cannot know, a more primitive time where sigmoïd were the only viable activation functions, where you had to write your C++ code for your gradient descent (for the learning phase) with your bare p̶a̶l̶m̶s̶ hands.
Good that time is now gone!
So, TensorFlow is a miracle of simplicity exposed to the user compared to that. Plus it has good community, good support among hardware vendors (GPU acceleration via Nvidia Cuda and also A̶T̶I̶ AMD ROCm) but also Google Cloud services (such as the excellent Google Colaboratory, a free environment where you can enjoy dedicated 12 GB with Nvidia Volta GPU or Google’s own TPU).
Will that be enough hardware muscles for only a cold, maybe unpassionate network to perceive the specifics of the two creators? Let’s find out!
By the way, what is a neural network, and how could it classify drawings?
Hmm, vast subject.
Your minion (the author of these lines) wrote some lines on that subject back in 2001 in a dedicated website (iacom.fr.st, now redirecting to some unclear Japanese contents).
I would have bet without question that this site has completely vanished into the ashes of the past eternity of the web, but to my great surprise the web archive project kept one copy back in 2013. Only the front page was saved…
Coursera course will reward your studying labours with a certificate, see this as a way to say thank you to Coursera for their otherwise free (& excellent) courses.
This ellipsis being made, let’s jump into the dataset preparation!
Dataset preparation
“All quality and no quantity would make our model a dull model.”
Nobody in particular
We have plenty of input data available. Btw, check out the superb volumes edited by Glenat (in France) with lots of annotation/anecdotes, some by Don Rosa himself for the collection dedicated to his work!
In particular if you sometimes fail to discover the hidden D.U.C.K. (Dedicated to Unca Carl from Keno) dedications in the first panels of Don Rosa stories.
Digitization
I have no doubt that your imagination makes this step unnecessary.
At the end of this stage, we had:
Stats
Carl Barks, in English
1158 files
1.35 GB
1.17 MB per file in average
Carl Barks, in French
1544 files
2.8 GB
1.8 MB per file in average
Don Rosa, in English
689 files
0.484 GB
0.702 MB per file in average
Don Rosa, in French
464 files
0.313 GB
0.676 MB per file in average
Heterogeneous sources, but nearly even FR/EN ratio (to limit possible learning bias)
Filtering
Whether we use a stack of only-dense layers (aka old school perceptron) or have mostly convolutional layers, input layer will always have a fixed size, exactly mapping pixel resolution of input images …
This means we have to feed our network during training phase with images of same pixel resolution.
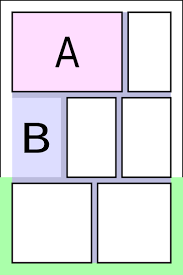
Terminology: A is a panel, B is a borderless panel, green area is a tier, rest is called gutters
A typical Don Rosa page
A slightly less usual, but not so unusual, Don Rosa page
A typical Carl Barks page, pretty regular 8 panels page
As shown above, terminology related to comics had to be fixed beforehand.
Also, regarding their respective styles, while Carl Barks has a purer, “classic” stroke of pen, Don Rosa, the engineer by training, has definitely profound sense of detail.
While Carl Barks will often sketch everyday life scenes, Don Rosa tends to lean towards epic setups. Naturally, there are many shades of grey in between, these are only tendencies felt by the human reader which I am.
Carl Barks sometimes deviates from 8 panels layout for dynamic scenes
Ideally, in order to compare drawing styles of the two authors, we would feed images with same resolutions.
One of the many famous Barks lithographies
Don Rosa also drawed full size images (sometimes for covers)
Both authors created full size images, which could be good samples. However, in case of Carl Barks the intention is more esthetic arts than support for story telling. His drawing style for lithographies is not similar to the one used in his comics. And we want to analyse the style used in the stories.
Also, due to the vast amount of work and time to create such images, there are much less samples falling in these categories.
So we really want to use for our dataset extracts from stories, not these full size images.
Page panel extraction : Kumiko
Kumiko is an open source tool is a set of tools using OpenCV’s contour detection algorithm to compute meta information on comic pages, such as panels.
A first attempt was done to extract all panels using this tool, but sometimes the algorithm went wrong (borderless panels are difficult to identify). But normalisation would have implied image scaling, and panel shapes are too different to have non destructive shape uniformisation.
So I decided to use images as input of neural networks (knowing that even reduced, such images may not be easy to digest …).
I went for a 1007×648 format, as a compromise between keeping details and not overwhelming our net.
Many pages are descriptive, fully-fletched with text and various layouts.
Also because of Don Rosa’s old engineer habits some pages tend to be … singular ;), such as these very precious ones, depicting Uncle Scrooge’s money bin secret plans:
Useful for the Beagle boys, but clearly not for us.
In order not to interfere with story telling pages, we use Kumiko to count the number of panels.
Kumiko json output
Some Python code helps us to automate the reading-kumiko-panel-meta-information-then-resizing part of input images.
Note, alternatively a rescaling layer can be added at the beginning of our network topology, but that would mean more data to be sent to Colaboratory (as original images are always larger than target resolution).
As can be seen, we only select images for which we detect more than three panels.
Results look good, only meaningful images are left.
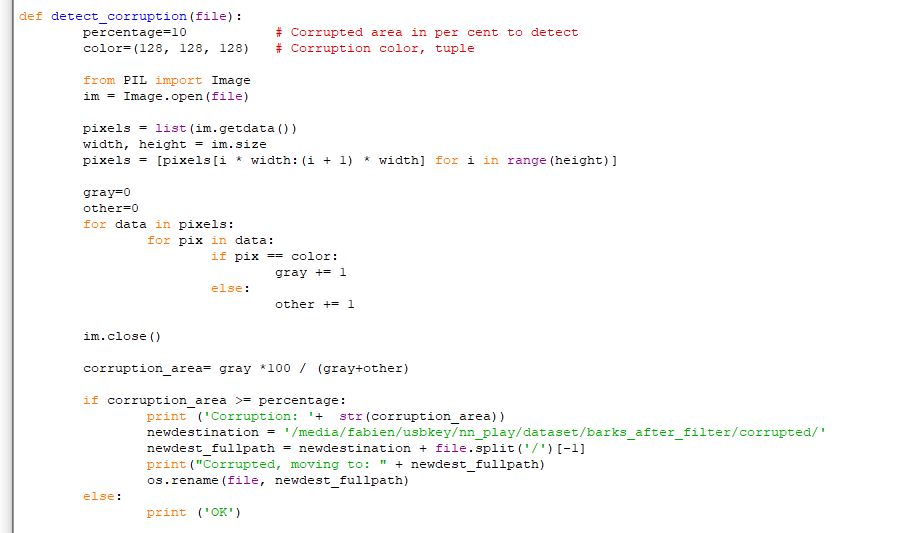
However, some visually corrupted images were still present.
Which were easily moved away using, again, simple python logic:
At the end, 1025 clean files remained for Barks/FR, 692 for Barks/EN, 598 for Rosa/EN and 377 for Rosa/FR.
Now, let’s get into Tensorflow!
As suggested previously, Google Colaboratory is well integrated into Google’s world. Notably Google Drive.
So after having pushed all files filtered and scaled by our previous python logic (~2.3 GB of .png files compressed in .tar.bz2) to a Google Drive folder, it could be mounted on a Colaboratory session.
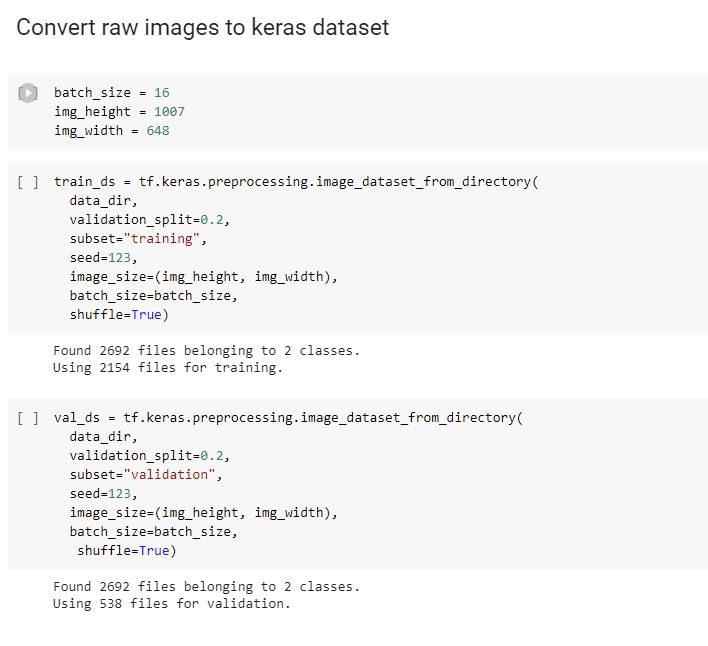
After some manual (re)exploration of the dataset, it is time to convert images to Keras input dataset format, and at the same time we want to specify the training/validation ratio.
As we have enough images, we reserve 20% of our sample for the validation:
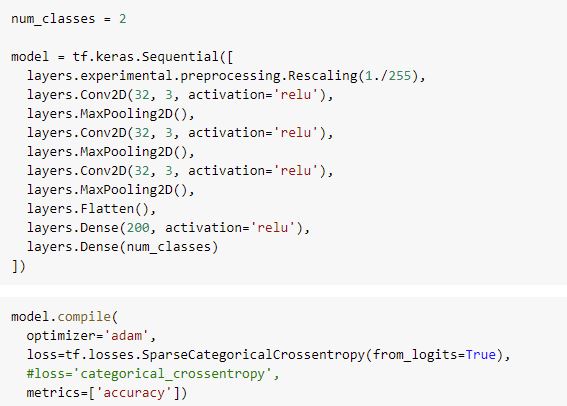
As we want to train the network to distinguish between Rosa and Barks images, we have two classes, one for each.
The two classes are implicitly detected after the names of the subdirectories from main dataset directories (one class for subdirectory barks/ and the other for rosa/).
Then comes the network topology.
Convulational networks tend to be better then multi dense-layers networks because their cubes-2-cubes internal transformations are somehow better at matching shapes.
Also, that smells newer than our retro perceptrons, so let’s go for it!
Chosen topology
Another disclaimer: this experiment was done in a brief amount of time, so no time at all was spend to experiment on various topology variants.
Only the number of neurons in last dense layer was changed a bit.
The rescaling layer at the beginning is just to normalize inputs from 0->255 ranges (RGB colors) to 0->1.
An interesting yet simple explanation for choice of relu activation functions can be read here.
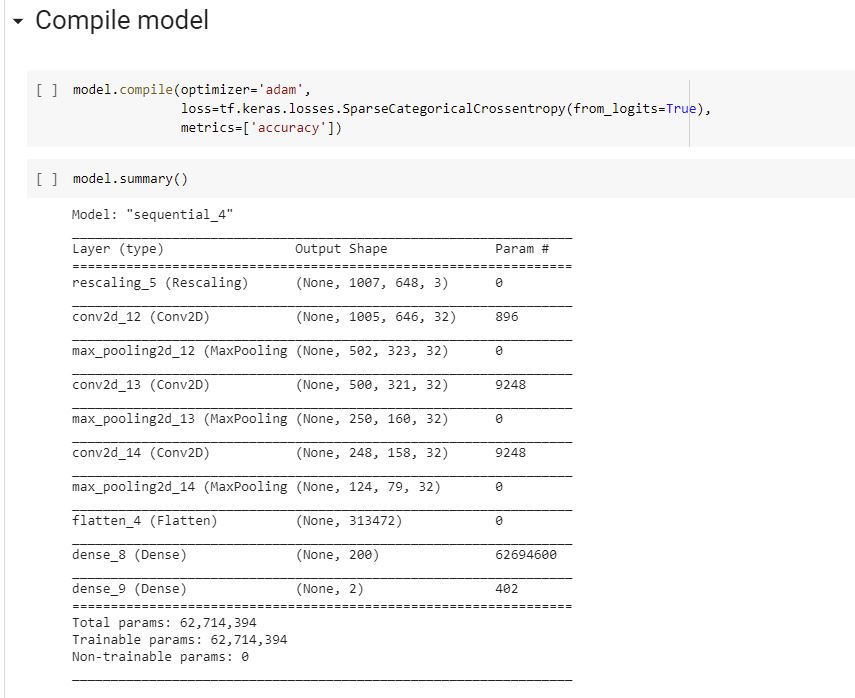
A summary of model as seen by Tensorflow
An important thing is to NOT prefetch images in training or validation sets – as it is often the case by default -, otherwise training will quickly cause OOMs (not enough RAM) the session, whatever the batch size is. Because our input images are too big.
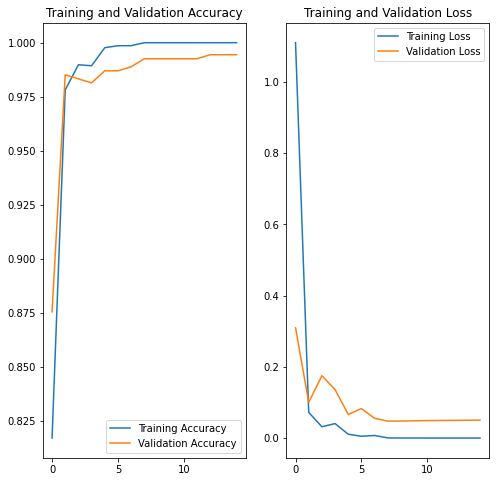
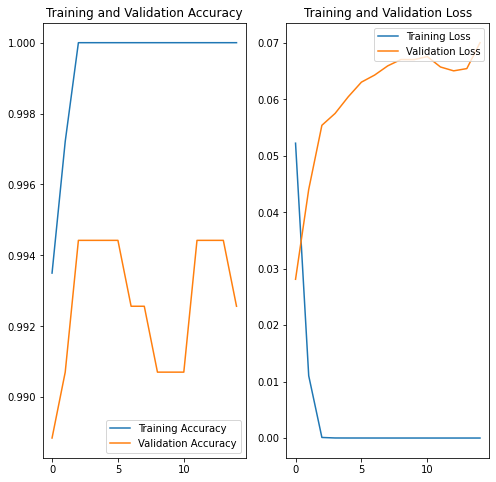
After 15 epochs (aka training steps) with batches of 16 images each, we converged to a surprisingly good 99.44% accuracy! 🙂
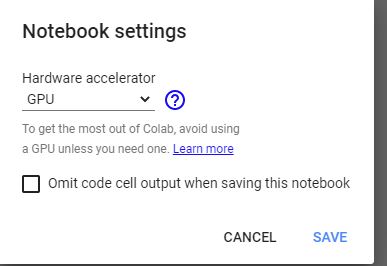
It took ~22 min to train with a GPU enabled session.
Be careful, by default session starts with no hardware accelerator… so make sure to select it at begining of your session.
Training and accuracy validation plots seem to show 15 epochs should be enough.
However, after attempting some predictions, it appeared another run of 15 epochs did improve results for tested samples.
Despite convergence towards lower accuracy overall:
Interesting is that during 2nd run validation accuracy fell a bit before reincreasing, and redecreasing (could be interesting to test with more epochs). This might be related to overfitting.
First more natural steps would be to stop learning as soon as validation accuracy drops, and training accuracy stops growing (slightly after epoch 15).
As we shuffled both training and validation sets, plus we dedicated a good part to validation (20%), it is not sure massively increasing the amount of training data would help a lot. Decreasing number of model parameters could possibly be key. Or alternatively, we could augment training/validation sets by performing image transformations such as scaling (could help identify full size drawings).
Maybe dropout could be used to reset some neurons at each training iteration. Also, playing with learning rate could be worth testing in a future session.
Funny enough, while reaching a lower accuracy (99.26%), results were much better on samples we used for prediction.
And now, let’s predict our Duck stories author
Let’s have a look together at some samples not part of training nor validation set found randomly on the net, and see whether prediction was correct or not (and in parenthesis the confidence factor), and my comments for each picture in legend.
Correct! (72% confidence) This one from Barks is interesting, this is an unfavorable case, with introductive format. But the model gets the correct answer 🙂
Correct (100%)! Easy one, very “typical” from Barks, nothing fancy here.
Barks, correct(100%)! Nothing fancy either.
Barks, correct (100%)!
Incorrect (99.86%) 🙁 A bit of disappointment for this one. This is an “epic” theme from Carl Barks, not so typical and more Don Rosa like. Even a human would have hesitated! Maybe an improvement of the training could change the result …
This was Barks, but identified as Rosa. Incorrect (100%) 🙁
Incorrect again (100%) 🙁 Looks like black&white comics don’t fit in learned Barks’ pattern … maybe such samples could be added to the training set (but there are few of them)
Incorrect (99.86%) 🙁 Disappointment. Clearly the colorisation is aged, but the trait is specific to Barks (and note this is the same story as in the 3rd picture)
Correct (88%) 🙂 A full page drawing from Don Rosa, correctly found. Nice!
Correct (100%) 🙂 A really newish style for this one, dynamic traits, vivid colors. Clearly on Rosa side, but could have probably been misidentified as other recent Duck artists.
Correct (58%). Another full page drawing from Don Rosa, correctly found, yet with less confidence. Obvious to the enthusiast however.
Correct (100%) 🙂 An easy win again for the model. Very dynamic Rosa style.
Correct (100%) This one from Rosa is too easy for our model!
Correct (100%). A full page image, with looots of details, typical for Rosa. 🙂 🙂
Correct (96%). “I know Don Rosa” something murmured 😉
Correct (100%), Rosa naturally
Correct (100%). Rosa in Danish, another big homeland for Duck stories.
Rosa at 100%: unknown artist. But I agree with the model.
Rosa at 99%. This time, I disagree! 😉
To conclude
This hands-on on “Deep Learning” was a very fun experiment for me, I really appreciated digging into that.
I’d say results are beyond my initial expectations, however I felt a bit disappointed when the learned model fell in some of the set traps (the “epic” Bark panel for example).
Now, to which extent the model learned the artistic style (whatever this means) or just the layout, the vividness of colorisation or drawing techniques (half a century separates the two!), difficult to say!
However the capability of the model to still have good predictions even for images slightly more exotic than the sometimes rigid 8-panels format used for lots of Carl Barks artworks is appreciable.
Now a next step could be to try other esteemed, modern artists such as Romano Scarpa. Would it still be distinctive enough for a simple model such as the one we trained here?
Ducks as drawn by Romano Scarpa
And who knows, maybe this kind of approach could pave way for artificially generated Duck stories in a not-so-distant future?
Bonjour à toi, puisses tu être fidèle lecteur ou pas.
Un petit post pour partager quelques expérimentations faites à la va-vite quand à l’optimisation des paramètres MultiPath TCP (via l’interface proposée par OpenWRT/OpenMPTCPRouter).
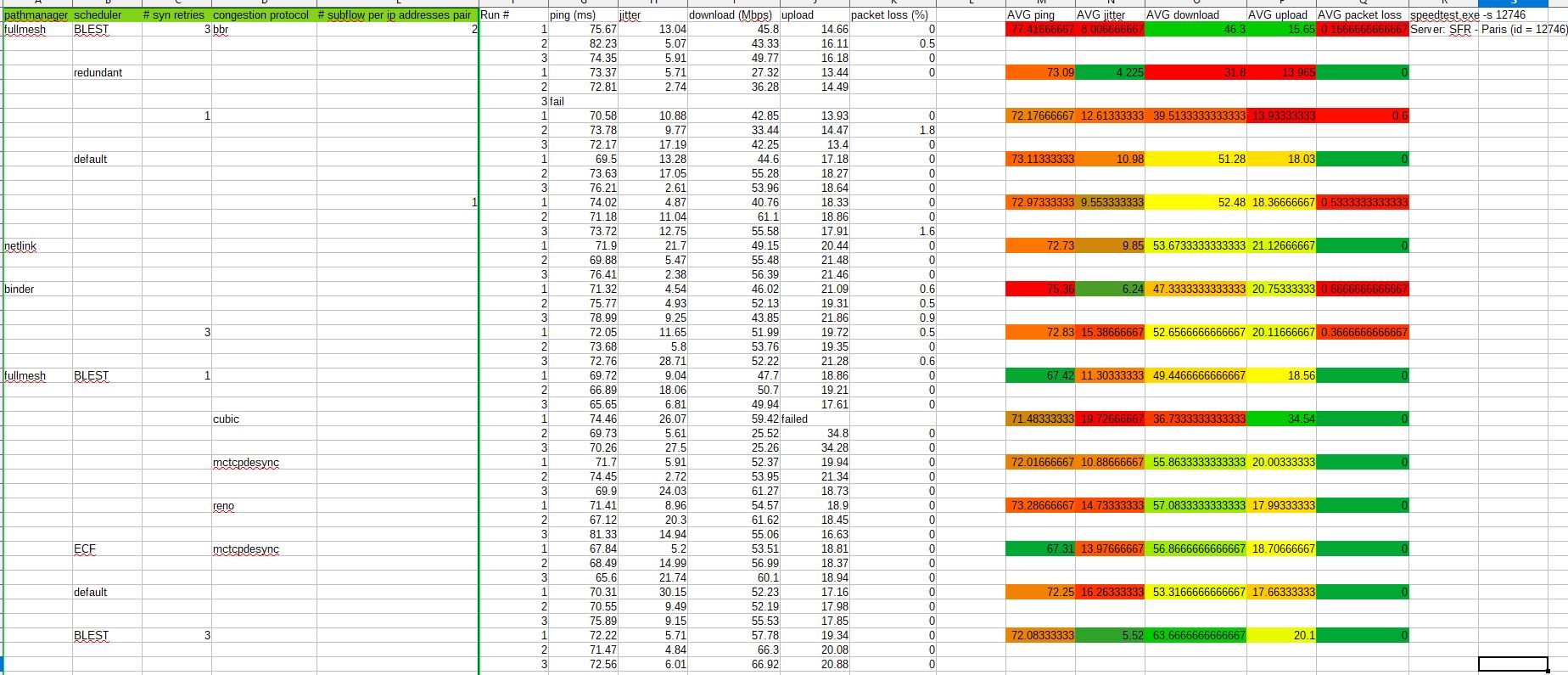
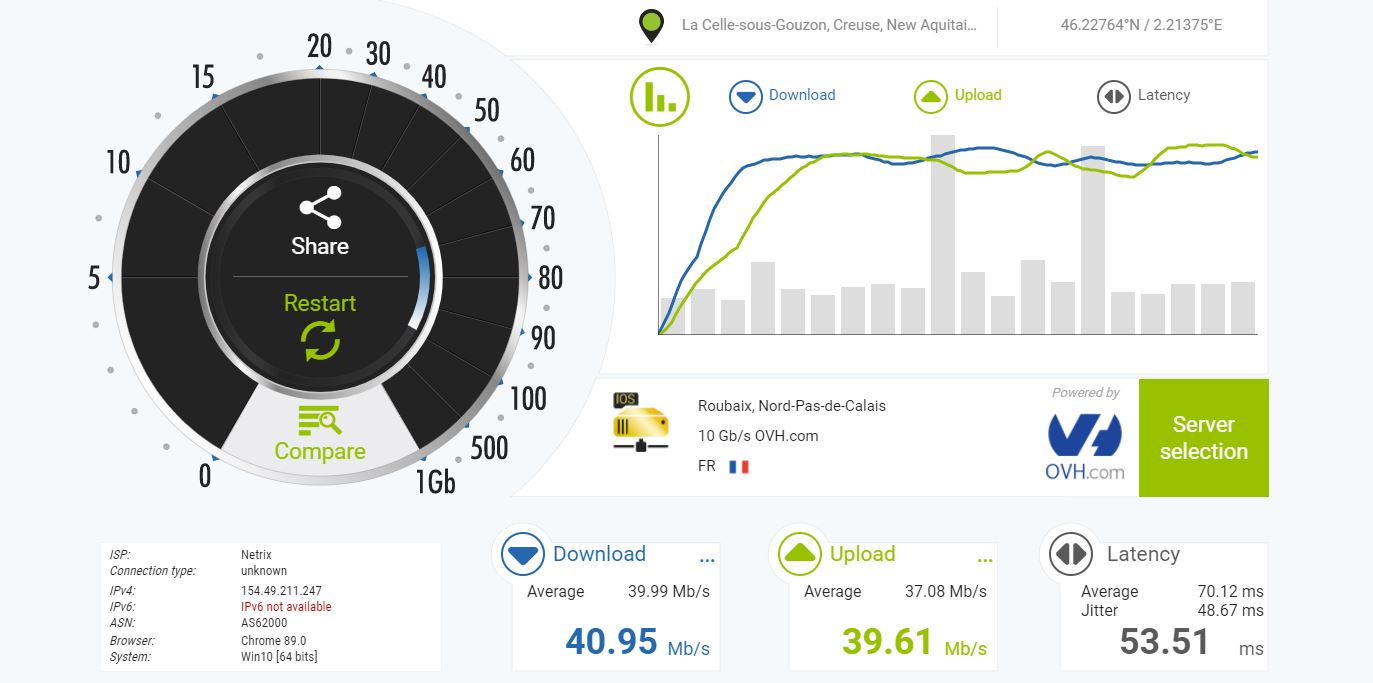
Voici sans tataouiner, comme diraient nos amis québécois, les résultats:
Alors énorme warning, le protocole ne rend en rien honneur à la rigueur forgée par plusieurs siècles de sciences statistiques (pas de calcul de variance par dimension, pas d’estimation d’incertitude).
Ceci dit, on pourra noter qu’en général un seul paramètre est modifié à la fois, avec 3 tests consécutifs par test. Sauf exception, auquel cas on se retrouve dans une configuration déjà testée (ou.. presque).
Les tests ont été fait de façon groupée, avec des conditions météos similaires (important, car nous parlons d’interfaces 4G).
On force pour tous les runs le serveur speedtest auquel une CLI se connecte pour mesure.
Un point intéressant, on pourrait très clairement envisager l’utilisation pertinente (pour une fois 😉 ) d’apprentissage supervisé (reinforcement learning par exemple) pour parcourir de manière non exhaustive la combinatoire, et de converger vers un objectif à définir.
Mais oui, quel est l’objectif?
Dans mon cas (multiplexage de connexions internet 4g pour télétravailler, essentiellement), l’objectif est de minimiser la gigue (aka jitter en anglais) et le ping, pour rendre le plus agréable possible les appels audio et vidéoconférences.
Ensuite, il s’agit de minimiser les pertes de paquets pour éviter de subites pertes de connections SSH ou VPN, par exemple.
Enfin, avec une moindre priorité, de maximer la bande passante en téléchargement (download et upload).
Succinte analyse
Le scheduler “redundant” est à éviter, il provoque un débit quasiment deux fois moindre que ses meilleurs comparses.
Même sentence pour le pathmanager “binder”, il est le seul à être accompagné de systématiques pertes de paquets.
Il serait intéressant de creuser l’impact du nombre de “subflows” par couple d’ip source/destination, même si l’asymptote semble vite atteinte.
scheduler: ECF (a priori meilleur pour les liens « aériens » comme la 4G)
congestion control: mtcpdesync
avec 2 subflow par pair d’IPs.
Les défauts étant resp. fullmesh/BLEST/cubic.
Mais
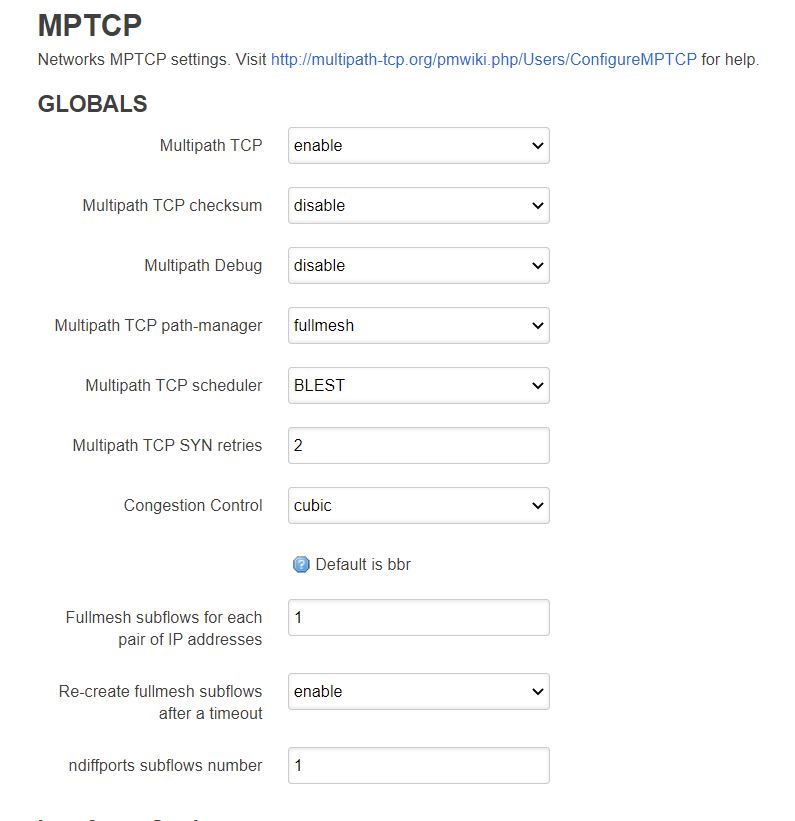
Depuis l’écriture originelle de cet article et l’incendie d’OVH qui a obligé une réécriture (rapide, il faut dire) des derniers articles de ce blog, j’ai découvert qu’après quelques heures, cette configuration mettait le VPS à genoux.
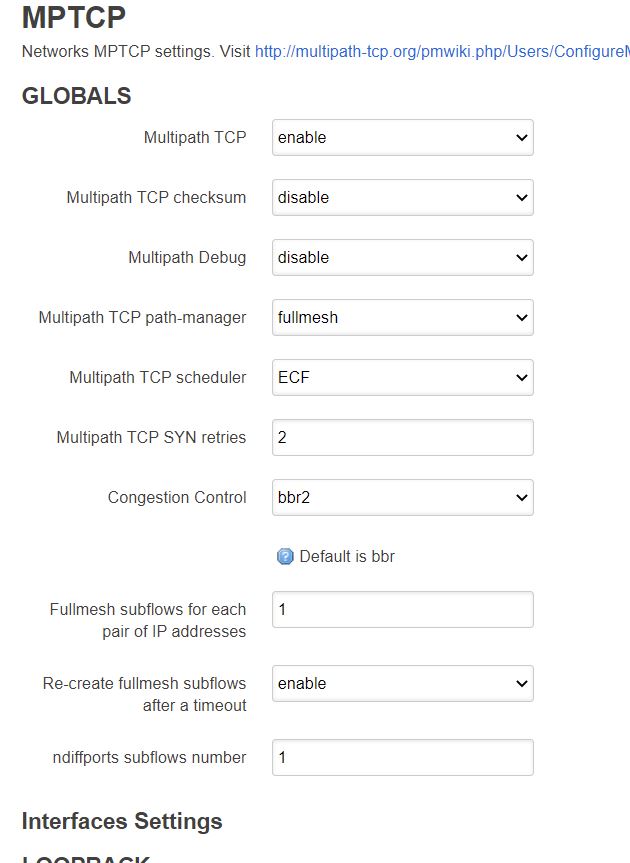
Après quelques itérations, en remettant la valeur par défaut au paramètre “fullmesh subflows for each pair of IP addresses”, soit 1, le retour à la stabilité était atteint.
D’autres itérations restaient toutefois nécessaires. En particulier, comprendre d’ou venait l’effondrement en performance (empreinte cpu/mémoire lié aux subflows, effet collatéral lié à du swap (si starvation mémoire..)..?).
« Conclusion »
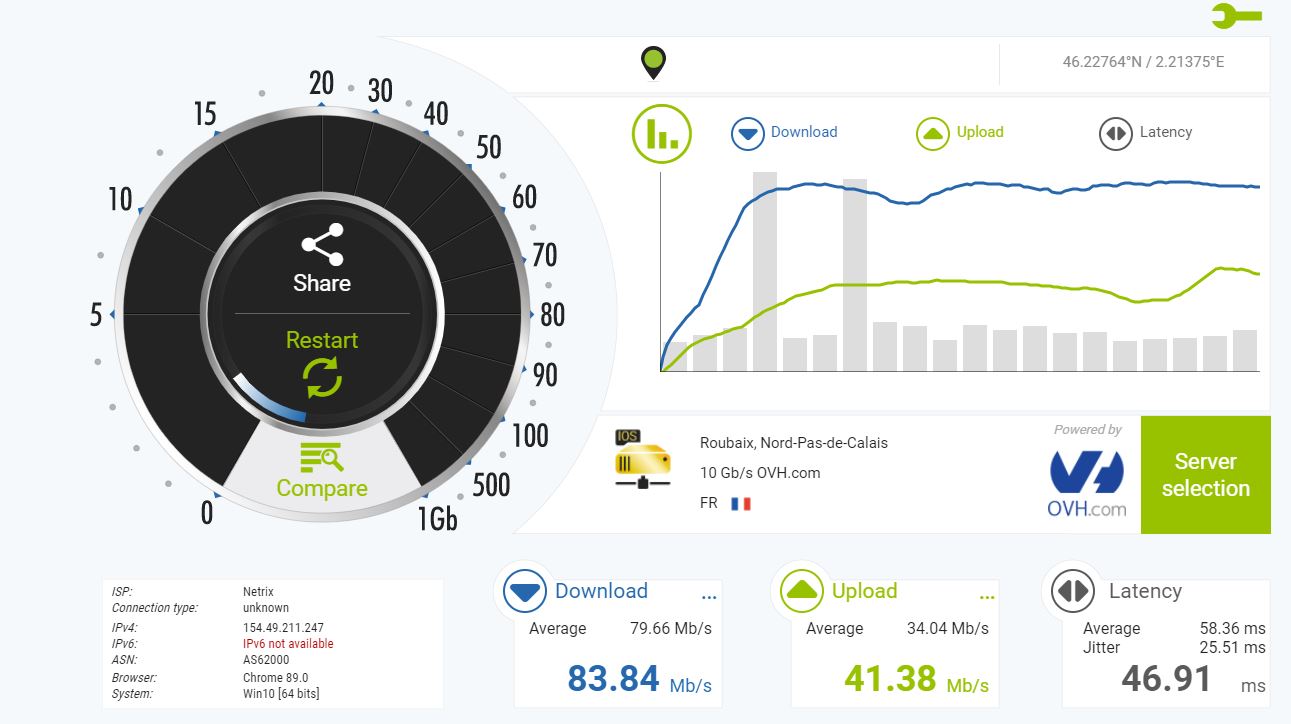
Les derniers essais fait sur un autre fournisseur VPS, avec 2 Go de RAM (plutot qu’un seul), ainsi que l’arrivée d’un nouvel algorithme de contrôle de congestion (bbr2 en beta), indique désormais le combo ECF/bbr2 en combo gagnant.
Avec les paramètres par défaut:
Voici les résultats:
Et avec le combo ECF/bbr2:
Des résultats excellents!
Note, le passage a 2 fullmesh subflows par paire d’IPs ne semble avoir aucun impact avec le nouveau VPS (2 vCores Intel Xeon E5-2690v3 + 2Go ram), alors au vu de l’impact sur le VPS précédent, j’ai décidé d’en rester à la valeur par défaut.
Note 2, les IPs des VPS OVH étant blacklistés par de nombreux sites/services (blink d’Amazon par exemple), le passage au nouveau VPS (pulseheberg) évite le paramétrage omr-bypass, qui permet de garder l’intérêt de la solution en toutes circonstances.
Note: l’article originale était illustrée de moults images, photos mais suite à la destruction du datacentre d’OVH de mars 2021 (ou ce blog était hosté, les images ont été perdues, seul le texte des articles a pu être sauvé)
Alors, ceci se veut le résumé d’une très longue histoire, celle de la quête d’une connexion “acceptable” dans l’arrière pays du Sud de la France.
D’abord, l’espoir
Après avoir trouvé la maison de nos rêves (mi 2019), maison qui coche un maximum de cases, un compromis a cependant du être trouvé quand à la connectivité vers l’internet mondial, si utile par ces temps.
Au point initial, nous avons:
absence de fibre (faut pas rêver), mais promesse de fibre l’année suivante (un tantinet optimiste, on attend toujours)
de la 3G avec les grands opérateurs nationaux
les précédents propriétaires qui se disaient “satisfaits” d’internet via Orange (en même temps, ils allaient vendre leur bien 🙂 )
et les différents services de test de débit ADSL qui se veulent rassurant
Zone gris très claire (mais pas blanche)
Parlons en, des services de test de débit à partir de l’ancien numéro de téléphone et/ou adresse postale.
Dans notre cas, nous avions 30 Mb/s via degrouptest.com, mais les autres (ariase, ovh..) sont d’accord.
ok, pas si terrible que ça que vous me direz!
Après abonnement sosh, nous plafonnons à 2.1 Mb/s, le vent dans le dos.
Soit 260 ko/s. En 2020, ça fait un peu tache. Surtout pour télétravailler..
Et en 3G, nous plafonnions à 8 Mb/s. Mieux, mais pas terrible..
Explication du faible débit ADSL
Sans rentrer dans les détails, une visite dans le NRA en question a permis de résoudre ce mystère.
En effet, le NRA était bien à moins de 900 mètres du domicile, et non, pas de souci de condensateurs ou autres défauts augmentant l’atténuation du signal.
Le souci venait de la nature du signal arrivant au NRA. En France, il semble que la plupart des NRA/NRO sont inter-reliés par des réseaux de fibre optique. Ce qui semble être l’hypothèse de (tous?) les services de test de débit, le goulot d’étranglement étant alors la distribution entre le NRA et l’abonné.
Mais non, certains NRA sont inter-reliés par des faisceaux hertziens propriétaires (autour de 1 Ghz). Dans ce cas, le débit total par NRA tourne autour de quelques centaines de Mbits/s, débit partagé par les centaines de lignes analogiques physiquement raccordées.
D’où un débit bridé à ~2Mbit/s par abonné dans ces situations.
Comment améliorer?
Déjà, nous pouvions abandonner la ligne terrestre.
Restaient:
la boucle locale radio
chère, pas assez performante, choix d’opérateur trop limité
le satellite
très cher, débits download/upload très asymétriques, quota ridicule et surtout ping inutilisable (pour audio/videoconférences, jeux…)
la 4G
perspective intéressante, mais
nous le la captions alors pas
quota important mais pas illimité
débit dépendant des conditions météos
possible variabilité de la qualité selon le nombre d’utilisateurs par antenne
en 4G, tout est NATé, et c’est très mal (si tu ne comprends pas encore le drame ce point, nous y reviendrons plus tard)
Mais j’ai été déçu par les données non actualisées, très peu précises (notamment sur le type et la position des antennes) et des estimations de “qualité” du signal fantaisistes (dans l’arrière pays, du moins).
Il suffit de sélectionner les antennes type 4G (et 5G si vous êtes rêveurs), et de vous trouver en vous aidant de la géolocalisation (code postal par exemple).
Avec www.antennesmobiles.fr, on peut repérer si l’antenne est activée ou devrait prochainement l’être, ainsi que la hauteur de l’antenne de chaque opérateur
www.cartoradio.fr est également très pratique, car il indique également les orientations des antennes (aussi appelées azimuts).
Par la suite, difficile de montrer une procédure précise sans dévoiler la localisation de votre serviteur-auteur de cet article.
www.cartoradio.fr, information que l’on peut croiser avec celles d’antennesmobiles.fr (avec l’ID)
Ici on voit l’azimut
On a une information plus ou moins précise, c’est variable, de la localisation/adresse de l’antenne.
Il suffit de prendre le fond de carte “carte du relief”, puis en mode 2D
Puis d’annoter votre maison, et les différentes antennes localisées grâce à leur adresse, ou alors si besoin en s’aidant du calque “Plan IGN” de geoportail:
Et là, la vue permet de facilement identifier:
les distances aux antennes
et bien sur, les antennes qu’on accroche sans relief au milieu
Pour ce dernier point, on peut aussi s’aider de l’outil de calcul du profil altimétrique.
On peut tracer une ligne droite sur le profil, pour bien voir ou se trouvent les obstacles
Et dans ce cas on voit que cela ne passerait pas.
A comparer avec les orientations fournies par cartoradio.
Il suffit de jouer un peu, en considérant aussi d’autres paramètres, comme les fréquences auxquelles on peut être candidat.
Une fréquence basse (700 Mhz, 800 Mhz) sera plus “passe partout”, car moins sensible à un air chargé en humidité, ou quand il pleut.
Une fréquence haute sera, si captée avec un bon ratio signal/bruit, synonyme d’un meilleur débit.
Aussi, il sera utile de repérer la densité en habitant autour ces antennes (présences de villages, villes, combien d’habitants..), et imaginer un “iso-signal” (c’est à dire voir les zones qui sont le mieux desservies par les antennes repérées, plutôt peuplées ou non) pour éviter les antennes trop fréquentées.
Étape 2: prendre le bon matériel
Après l’étape 1, tu sauras cher lecteur quelle est ou quelles sont les fréquences avec lesquelles tu vas travailler.
Fort de ces informations, tu trouveras utile ou non de t’orienter sur un routeur à aggrégation de porteuses (attention, si l’opérateur propose lui même 1) plusieurs bandes de fréquences sur l’antenne considérée et 2) s’il propose l’aggrégation de fréquences), aussi appelée 4G+ (800 Mhz + 1800 Mhz chez Bouygues, 800 Mhz + 2600 Mhz chez Bouygues, Orange, SFR, ou 1800 Mhz + 2600 Mhz chez Bouygues ou Free) ou 4G++ (3 bandes de fréquence).
Pour les détails sur le hardware qui va bien, je t’invite à regarder ce site: https://routeur4g.fr/
J’ai pour la part jeté mon dévolu sur cette antenne (très efficace, un peu chère) et celle ci (sensiblement moins efficace, moins chère).
Branchées respectivement sur un routeur 4g Huawei B715 et une clé 4G E3372h-607.
Étape 3: choix des opérateurs
Il suffit de suivre les “bons plans” sur les forfait 4g.
Dans notre optimisation, nous avons un forfait crédit mutuel mobile à 25 euros/mois avec “data illimitée” (en vrai 2000 GO/mois) et une deuxième carte sim greffée à un forfait Bouygues (option facturée 2 euros/mois).
Edit: On m’a signalé que le forfait c’redit mutuel mobile n’est plus dispo au même tarif. Je recommande de surveiller les bons plans en la matière, qui reviennent régulièrement.
Il faut être stratégique sur l’assignation de l’abonnement au forfait.
Le forfait le plus gros, sur le couple routeur/antenne le plus performant (car il se videra plus vite).
Étape 4: l’Aggrégation
Le lecteur intéressé, facétieux et attentif que tu es aura remarqué que l’auteur de ce post fait référence plusieurs fois à deux moyens d’accès à Internet.
Il existe des routeurs wifi qui permettent une aggrégation de façon plus ou moins native (par ex, un asus RT-3200 sert ton serviteur, qui propose un link aggregation).
Mais en vrai, ça ne marche pas bien.
Car c’est soit une aggrégation de connections TCP – qui permet de maximiser la bande passante uniquement dans certains cas “faciles” (protocoles nativement multiconnections comme torrent), ou alors du fail over (si un lien tombe, l’autre est utilisé, ce qui revient à bien cher pour cet usage uniquement).
Il existe quelques rares options commerciales, comme overthebox, qui permettent une aggrégation plus basse, au niveau TCP.
Mais les tarifs autrefois abordables ne le sont plus (150 euros HT de boitier + 20 euros HT, au moins cher, avec 100 Mb/s max en aggrégation.
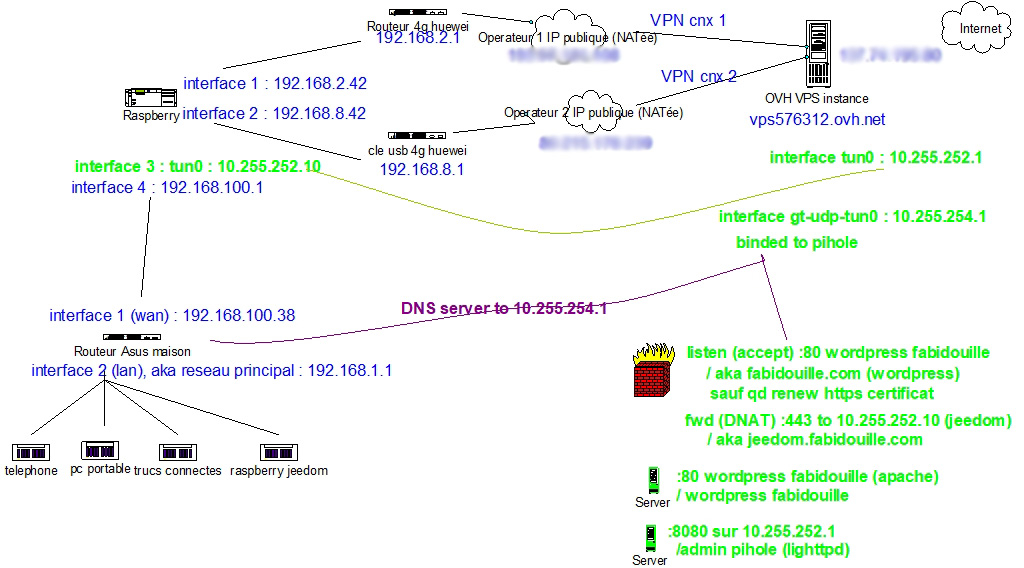
votre réseau local est physiquement branché sur un raspberry (d’autres hardwares supportés, mais moins bien), sur lequel une distribution OpenWrt customisée est installée, et connecté via VPN à un serveur disposant d’une IP publique, et préférablement d’une bande passante confortable. Un VPS est un excellent choix.
Je recommanderais un VPS OVH (à partir de 3 euros TTC/mois), mais l’offre est pléthorique.
Comme votre dévoué fabidouille avait déjà un VPS (pour hoster ce site notamment), le coût de l’opération s’avérait minime.
La redondance offerte par Multipath TCP rend accessible le multiplexage inverse de ressources, ce qui permet d’améliorer la cadence (throughput) de TCP jusqu’à atteindre la somme des cadences en profitant des performances des différents canaux physiques au lieu de n’en utiliser qu’un seul, comme c’est le cas en TCP standard. Multipath TCP est en plus rétro-compatible avec le TCP classique.
Pour l’installation de la partie serveur, ça se passe ici.
Et pour la partie client (raspberry), ça se passe là.
Autre immense avantage, la possibilité de plus avoir son adresse IP NATée, ce qui serait le cas en 4G classique.
Pour le dire simplement, pour économiser le nombre d’IPs v4 attribuées aux clients 4G, une adresse publique est partagée par de multiples utilisateurs, via un réseau NAT. Ce qui rend l’exposition de service impossible, sans tiers partie.
Mais cette approche permet de profiter de l’adresse IP v4 statique (ainsi que les noms de domaines associés éventuellement) à son VPS, ainsi que d’autres avantages (par ex protection DDOS OVH).
Attention, attention
Si ton sens de l’économie est assez aiguisé, tu souhaiteras peut être utiliser ton serveur VPS pour héberger un site, un accès https domotique, des accès à d’autres services exposés sécurisés, ainsi que des services non exposés internes (comme DNS avec Pi-Hole).
Dans ce cas, il faut faire attention à
par défaut, l’installation de pi-hole va se faire dans /var/www/html, qui sera possiblement déjà occupé (penser à backup avant d’installer pi-hole, qui n’aura pas la courtoisie de prévenir). Aussi, lighttpd héberge par défaut Pi-Hole et apache wordpress. Il est toutefois possible d’utiliser apache pour Pi-Hole (testé&validé par votre serviteur). Autrement, bien penser à aligner les /etc/lighttpd/lighttpd.conf et /etc/apache2/apache2.conf avec les /var/html respectifs.
il arrive parfois que les adresses des interfaces VPN ne soient pas alignées. tun0 est utilisée côté VPS pour le VPN. Bien penser à noter l’ip de celle ci, et de la repliquer dans /etc/lighttpd/external.conf du VPS pour les services publiés en interne.
bien entendu, la configuration pare feu (shorewall) sera avantageusement modifiée en ACCEPTant des services publiées (80 par ex) et DNATant les ports 443 (service domotique https securisé) et 65101 (shadowsocks proxy sécurisé avec redirection TCP)
on pensera bien à configurer le routeur “principal” wifi pour qu’il tape sur le service interne DNS
Au final, un petit schéma (simplificateur 😉 – on ne montre pas toutes les interfaces réseaux côté client/VPS) pour ne pas trop s’y perdre
Du fait de quelques instabilités et surtout un peu de gigue (variations qui pouvait être importantes dans l’étalement, la “périodicité” des paquets TCP), l’utilisation du scheduler “redundant” (plutôt que BLEST) donne de bons résultats pour le moment.
Quelques infos intéressantes ici sur l’implémentation de ce scheduler, issue d’un projet de l’Union Européenne en sécurité: https://github.com/i2t/rmptcp
Aujourd’hui, un petit déballage sur un achat fait sur gearbest deux ans après l’achat, un prometteur objet titré “Utorch LED Mosquito Killer Lighting Bulb – White 220V”.
Alors obtenu contre 5.22 euros, j’ai eu une triple surprise en le recherchant alors que j’écris ce billet.
cet objet est encore en vente 😯
son prix a augmenté (6.75 euros)
les commentaires sont bons!
Déjà, la boite!
Si on met de côté le régal que des traductions de ce genre d’article, on voit les logos CE (pour Chinese Export » 😉 ?) et Interdit aux petits oignons dans une tente (ou.. non dimmable).
qui nous rassurent d’emblée.
Ouvrons la boite..
Déjà, à peine la boite ouverte, deux morceaux en tombent.
Un couvercle en plastique et le corps de l’ampoule.
Et oui, les deux parties n’étaient pas solidaires en sortie de boite.
Zoomons
Wahou!
des socles 100% plastique (probablement pas ignifugés, mais je ne testerai cet aspect que si la barre des 400 demandes est atteinte!).
des soudures plus qu’hasardeuses (rappelons que la tension secteur passe par les deux points de phase (L) et neutre (N) indiqués par des flèches vertes.
justement des soudures hasardeuses, neutre et phase ne sont séparés que par 1.8mm (imaginez par temps humide, avec la conductivité qui grimpe..), et observer les bouts des câbles dépassant tranquillement des pâtés de soudure (au plomb, assurément). Foufou.
En fausses couleurs, pour augmenter le contraste, on comprends un peu mieux le schéma. A analyser dans le détail, mais il semblerait que la conversion AC->DC se fasse par un simple pont de diode (M310F), sans séparation primaire/secondaire par transfo.
Voilà, le quickie est déjà terminé.
Qu’en déduire? Au minimum couper les bouts de fil pour limiter les risques de court circuit, et éviter de la laisser dehors sans protection..
Encore un format rapide, non que je fusse un homme pressé, ni même si occupé (un peu quand même), mais j’ai une nette tendance à agir plutôt que rédiger ici.
L’exercice est pourtant amusant, stimulant, alors je m’y prêterai encore.
Dernières occupations que j’aurais aimé narrer
Caméra de recul sur Mazda
Fort de l’expérience de démontage de la Mazda, mère d’un précédent article, j’ai voulu ajouter une caméra de recul au véhicule, en espérant qu’elle serait joliment intégrée au système de divertissement natif, comme si j’avais eu cette option à l’achat.
Spoiler: ça a fonctionné, brancher sur l’entrée analogique du connecteur principal sur lequel les RX/TX dont j’avais parlé lors de ce précédent article. Dans un futur article, je détaillerai la procédure, les références, ainsi que les détails quand à l’alimentation VCC de cette caméra, et les déboires pratiques que j’ai rencontré pour la fixer avec discrétion au dessus de la plaque d’immatriculation.
Ces déboires ont impliqué notamment ma familiarisation avec un logiciel de conception 3d axé pièces mécaniques, DesignSpark Mechanical.
Avec un peu de ceci
Puis un peu de cela:
Le but étant d’imprimer une pièce pour placer la caméra (de forme cylindrique, d’où le trou), avec des ergots sur les côtés pour clipser la pièce. La structure arborescente visible sur le deuxième dessin représente un pont pour permettre de contrer la gravité pendant l’impression.
Je rentrerai plus dans le détail une autre fois, ainsi d’ailleurs peut être que l’imprimante 3d que j’ai montée il y a déjà un an de dela, une Anet A8 lowcost mais efficace (à l’époque acquise pour 110 euros frais de port inclus).
Ressusciter DJI Phantom 4 et sa batterie
Un ami (qui se reconnaîtra, merci :mrgreen:) m’a donné un DJI phantom 4 qui ne vole plus, même avec une batterie fonctionnelle (que je n’ai pas) et une batterie non fonctionnelle.
Un projet en cours consiste en leur réparation.
Une bonne piste est concernant la batterie sera mise à l’oeuvre, dès qu’un peu de temps daignera me trouver.
Sujet de l’article
Alors, le quickie du jour, c’est donc un diffuseur d’huiles essentielles de qualité, le bien nommé Excelvan LM-S1, qui fonctionne par nébulisation. Plus précisément, un procédé qui évite l’échauffement d’une flamme, la vaporisation par ultrason, avec ou sans eau.
Comment donc alors?
Attendons le démontage.
Voilà, un bête moteur continu 5V, qui meut une micro pompe à air pour aspirer l’air de la fiole d’huile essentielle et la projeter dans les airs.
Au fait, pourquoi l’avoir démonté, ce diffuseur?
Bonne question!
Parce qu’il ne marche plus. Plus spécifiquement, il s’allume (la LED bleue en témoigne), mais il reste muet, silencieux, et inactif.
Réparation
.. plus simple que prévue, (mal 🙄 )heureusement!
Après avoir branché le moteur sur une source de tension 5V pouvant fournir jusqu’à 1A, le moteur restait désespérément muet.
En tenant d’exercer une rotation sur son axe avec mes doigts, j’ai senti une très forte résistance, probablement causée par des résidus graisseux/résineux d’huiles essentielles.
Une méthode consiste à tenter d’ouvrir le moteur (opération délicate), et d’y séparer les éléments (opération très délicate), dégraisser avec de l’alcool et enfin de remonter le tout (opération à peine surmontable).
J’ai préféré opter pour une solution plus ..efficace:
Étape 1: on nettoie au nettoyeur vapeur
Étape 2: on nettoie au WD40
Étape 3: on chauffe (c’est quand même bien d’enlever l’eau restante)
Pas trop quand même, moins longtemps que sur cette vidéo – le pistolet à air chaud était réglé à 300 degrés Celsius.
Étape 4: on teste si ça marche
Étape 5: on démonte, et au cas où, on diffuse un peu de WD40 (attention, éviter de respirer les vapeurs dans la mesure du possible)
Désolé pour la qualité des vidéos et le format portrait, la faute au nombre de mes mains (2).
Pas mal de choses depuis la dernière fois, des choses non bidouillesques, des choses bidouillesques mais pas (encore?) racontées et une chose bidouillesque que je m’en vais vous raconter maintenant.
« Bien », tu me diras lecteur restant à convaincre, « mais pourquoi en étaler la dessus? »
Il se trouve qu’il y a quelques semaines de cela, j’ai réitéré l’opération pour ajouter -notamment- une fonctionnalité des plus intéressantes pour le grand utilisateur d’app android podcasts/deezer que je suis: Android Auto. AInsi que mettre une séquence de boot animé à la Matrix -parce que je le trouve joli- et un fond d’écran représentant un système stellaire imaginaire -pour la même raison-.
Après une partielle réussite, le seul défaut subsistant consistait en un défaut majeur d’affichage du lecteur audio legacy, que j’ai souhaité corriger en tweakant plus que le tweaker, et là les foudres de l’enfer commencèrent à pointer le bout de leur nez.
En effet, le jour même du retour d’une semaine de vacances -un dimanche, ce détail aura son importance plus tard-, je me lance dans cette « correction finale » qui se clôt par une impassible, fatale, implacable séquence de boot qui ne peut finir. Infinie déception.
Sans le décrire, le système sur lequel se base l’outil de tweaking mentionné plus haut ressemble aux autorun des anciens (et peut être actuels?) Windows.
L’outil lancé, il se manifeste en ouvrant via un simple appel de script sh (oui, le système audio/video/gps visé par ces modifications tourne sous un linux custom) des fenêtres sur l’écran embarqué dans la voiture pour manifester ses activités.
Une des premières actions prises alors fut alors d’activer la création d’un access point (AP) wifi par la voiture (l’utilisation standard est inversée: la voiture se connecte typiquement à un AP crée par un smartphone pour mettre à jour certaines données) et d’un accès SSH, démarche toujours assistée par l’outil de tweaking.
Opération faite sur l’autoroute de retour des vacances, bien sûr ni laptop ni téléphone au volant.
Cet accès m’a permis d’accentuer nettement la situation dramatique dans laquelle je m’embourbais, car il me délia l’accès au système de fichier, en tant que root, de la voiture.
La sagesse des premiers instants s’est alors vite estompée, car quelques opérations que je ne raconterai pas ici – qui impliquent chose à ne jamais, jamais faire de lancer un script qui parait bien trouvé au hasard d’un forum qui me causa la disparition pure et simple, sans backup, de fichiers critiques pour le système – me firent dans un premier temps perdre l’autorun (aucune fenêtre ne s’ouvrait après l’insertion de clés USB dôtées de l’autorun), et dans un deuxième temps l’accès SSH.
Je me retrouvai avec le système de divertissement HS (sans GPS, audio, possibilité de modifier le comportement de l’éclairage de la voiture, etc…), qui essaye misérablement de booter sans y parvenir.
Le destin ayant toujours le moyen de garder le sourire, il s’arrangeât pour que cette mésaventure arriva le jour même des trois ans d’anniversaire de l’achat de ma voiture. Et la garantie était, bien entendue, de trois ans exactement.
Le lendemain matin, j’arrivai à la première heure, dépité, à mon concessionnaire Mazda qui m’annonça qu’en effet la garantie était dépassée depuis 8 heures.
Le responsable local tente la procédure de recovery qui consiste à mettre le système dans un mode spécial pour mettre à jour le firmware (en appuyant simultanément sur les boutons musique+mute+favoris), sans effet. Peut être est ce du à la suppression du fichier sm.conf, qui semble séquencer le démarrage post boot kernel de certains composants importants..
..puis un technicien dédié confirme, on m’annonce que cela n’est pas réparable, et qu’il faut commander le nouveau module entier.
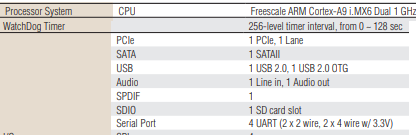
Quelques mails et jours plus tard, un geste exceptionnel du constructeur me permettait d’obtenir un nouveau CMU (c’est le nom de la boite qui comprend l’écran, l’ampli audio, le SOC ARM (un Freescale iMX6, un cat /proc/cpuinfo permet de le trouver) orchestrant tout cela) avec un rabais de 80%, c’est à dire 263.84 euros TTC au lieu de 1099.34 euros HT (prix standard Mazda), sans la pose bien entendu.
Nouvellement motivé par ce gain de près de 300 euros, je m’attelle à la tâche de tentative de réparation du système dit irréparable.
Tout système linux ou même pas linux en général, qu’il soit compliqué (smartphone android, système audio/gps/video voiture, gros routeur, tvbox…) ou plus simple (sonnette) permet quasi systématiquement une communication série.
Une série de 0s et de 1s, échangée par deux fils, un pour transmettre (Tx) et un pour recevoir (Rx).
On branche le Tx du transmetteur sur le Tx du récepteur, le Rx du transmetteur sur le Rx du récepteur.
Le 0, c’est le niveau de la masse (GND), comme toujours.
Le 1, c’est soit une différence de potentiel de 5v ou de 3.3v par rapport à la masse. C’est ce qu’on appelle le signal TTL.
Il est capital de savoir si on parle avec des signaux 5v ou 3.3v, car si le périphérique comprend le 3.3v et qu’on lui parle avec un niveau TTL 5v, au mieux ça marche pas, au pire on casse tout.
On trouve aisément sur le net que sur le Freescale MX6, il s’agit de TTL 3.3v :
Donc ma mission, acceptée par défaut, sera de
démonter le CMU
tenter la communication en mode TTY/console via l’UART (qui permet la communication série) pour
restaurer les fichiers d’origines.. ah oui j’ai oublié cette partie.
Récupérer les fichiers d’origines
La commence une croisade, celle qui consiste à récupérer les fichiers critiques modifiées par l’outil de tweaking, puis malencontreusement supprimés, qui se sont avérés être:
/jci/opera/opera_home/opera.ini
/jci/scripts/stage_wifi.sh
/jci/sm.conf
/jci/opera/opera_dir/userjs/fps.js
Version brève:
il faut récupérer dans un lieu mystérieux et miraculeux, c’est à dire ici. Pour chaque paire de fichier, il faut prendre le .up le plus volumineux. Ce .up est un .zip.
il faut trouver où y sont cachés les fichiers miraculeux.
Comme il est dommage de faire simple quand on peut faire compliqué, cet endroit est dans le répertoire racine rootfs1upd\, on y trouve:
Dans le .dat du premier fichier .gz, à nouveau une archive cachée, on trouve un fichier si bien nommé: e0000000001. Dans lequel, qui se trouve être encore une archive cachée, qui contient un répertoire nommé: . .Oui, il se nomme point (« . »). Dans lequel on trouve l’arborescence rootfs du / du système.
N’oublions pas, une des archives est protégée par mot de passe. Et comme je suis sympa, voici le césame: 5X/9vAVhovyU2ygK (si, si).
Extraire la bête
En retirant la longue bande (en tirant vers 1, puis 2, …) en espérant accéder au démontage du CMU.
Et bien c’était une mauvaise idée, on y accède pas par là malgré une alléchante vis.
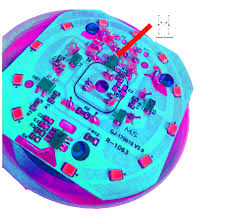
Il faut en fait déclipser la partie indiquée en rouge dans la photo suivante:
En faisant très attention à ne pas rayer/érafler le plastique, très fragile. J’ai utilisé le capuchon d’un stylo bic, très efficace et propre.
L’étape suivante est de déclipser la partie derrière l’écran, toujours même technique, cela part plus facilement.
On alors facilement les deux vis sous l’écran qu’il faut enlever avec une clé à douille avec une allonge (il faut un certain couple pour les desserrer) de taille 10.
Puis il suffit de déloger le CMU de son compartiment, en le tirant vers le haut (il faut un peu insister).
On remarque l’abondance de bandes adhésive (gros scotch marron) pour éviter de rayer la console en plastique, vu que le CMU est en métal.
On trouve des références techniques un partout plus ou moins claires sur le net, qui correspondent en vrac à des mazda 3, 6, CX-5, versions américaines, européennes, versions <2015 ou plus récentes, plus ou moins révélatrices de son modèle.
Communiquer avec la bête
Alors, sur le net on trouve de tout.
De ceux qui conseillent de souder directement les Tx, Rx sur le PCB de la carte mère:
Ceux qui utilisent un programmeur pour réécrire la flash soudée qui contient le système.
Et, enfin, les sages qui peuvent se le permettre qui rusent en ajoutant des fils dans le connecteur qui contient des slots pour les Tx Rx:
Mais je vois pas de pins Rx et Tx sur mon PC, comment je fais Monsieur?
Alors en général, on utilise un convertisseur usb TTL, soit 5v (bon pour nous) soit 3.3v (pas bon pour nous).
On en trouve des centaines entre 1 et 2 euros frais de port inclus sur aliexpress avec les mots clés « TTL USB converter 3.3v ».
Mais la proposition de Mazda (80% de remise) était valable seulement 30 jours, je ne pouvais donc pas me permettre d’attendre ce convertisseur TTL.
Alors première solution envisagée: sortir un vieux laptop pentium 2 trouvée dans une poubelle avec un port série. Potentielle grosse erreur, car les niveaux TTL peuvent être 12v sur les PCs.
Autre solution, utiliser un arduino (qui n’en n’a pas quelques dizaines chez soi?) comme un convertisseur TTL.
En effet, les Arduino Uno sont composés d’un Atmel 328P (le micro controlleur) et d’un chip FTDI convertissant USB (vers PC) <=> série (vers microcontrolleur).
Une astuce, que j’ai essayé, consiste à court-circuiter la borne RST (reset) du microcontrolleur à la masse, pour « désactiver » le microcontrolleur, et n’activer que le chip FTDI USB série.
Astuce que j’ai essayé, qui n’a pas marché. Oui, c’est bien la peine que je vous la dévoile..
Ce qui a marché pour moi, simplement faire un programme (sketch) arduino suivant:
Les arduino uno fonctionnent avec un TTL égal à la tension d’alimentation, ici 5v.
Contre astuce 1: utiliser des circuits convertisseurs de niveau logique 5v<->3.3v trouvable pour moins d’un euro sur les sites asiatiques. Ou se le faire avec un pont diviseur de tension (résistances).
Contre astuce 2: Il se trouve que j’ai un vieux clone chinois d’Arduino, le Funduino qui a comme pouvoir magique d’avoir un switch physique qui permet de basculer ses niveaux TTL de 5v à 3.3v:
Il n’y avait plus qu’à connecter l’ensemble:
J’ai testé avec succès avec des fils classiques dupont de breadboards.
Ma technique: dénuder de 3 bons centimètres, faire passer le fil à l’intérieur de la fiche pour faire dépasser les fils et les rouler à l’extérieur, pour s’assurer que le contact se fasse (il n’y a pas d’encoche metallique dans la fiche, car ces pins ne sont pas sensées être utilisés).
Que le texte défile
Un putty/xshell/n’importe quel soft qui permet de communiquer en RS232 (série) 115200 bauds, 8 databits, pas de bit de parité, et 1 stop bit plus tard et la magie se passa.
Première déconvenue
Pour transférer en série les 4 fichiers textes mentionnés plus haut,
après avoir
déactiver le watchdog timer noyau: echo 1 > /sys/class/gpio/Watchdog\ Disable/value (plus d’infos ici pour comprendre ce mecanisme watchdog et le lien avec /sys/class/gpio)
et remonter le rootfs en écriture: mount -o rw,remount /
un
cat > lefichier
suivi d’un copie colle terminé par un ^D (control D) fit le job.
Après redémarrage toutefois, cela ne redémarrait toujours pas.
Première déconvenue, donc, et coucher à 1h50 du matin.
Soupir, espoir
Le lendemain, plein d’espoir, surgit l’ombre du failsafe.
Le failsafe est l’un des deux .up qui composent le firmware. Le failsafe est un système rudimentaire qui permet de mettre à jour le système, qui est normalement appelé par le process qui s’active avec la combinaison Musique+mute+favoris décrite plus haut, qui ne fonctionnait plus dans notre cas.
Il y avait une page sur le net qui expliquait comment forcer ce mode en hardware, ici.
Désormais, cette page débouche sur ce message obscur: « These web pages were intended for sharing information from Electrical Engineer to fellow Electrical Engineer. They have now been removed due to people who ignore warnings, erroneously think that they can pretend to be an experienced Electrical Engineer, and think that following a haphazard subset of steps in a dangerous process (that they were warned not to do) is somehow equivalent to performing all of them. »
Non intimidé, une recherche via le site – fabuleux dit en passant – web.archive.org (l’internet wayback machine) montre 14 snapshots entre juin 2016 et janvier 2018, le dernier qui montre l’information date du 8 mars 2017: https://web.archive.org/web/20170308064828/2x4logic.com/invokefailsafe.html
La on apprendre une procédure réservée aux initiés qui explique comment l’auteur a, à l’aide d’un bus pirate, forcé le boot depuis le failsafe. Et notamment il explique que le bloc boot-select est configurable via un état forçable dans mtd (mtdblock1).
Et oh surprise, un script configure_flash.sh trouvable dans le rootfs contient une fonction switch_ibc, qui en fonction de l’entier qu’on lui passe configure ce mtd : 1 boot normal (système de fichier linux rootfs), mais sinon (2 par exemple) : boot sur failsafe.
Bonheur
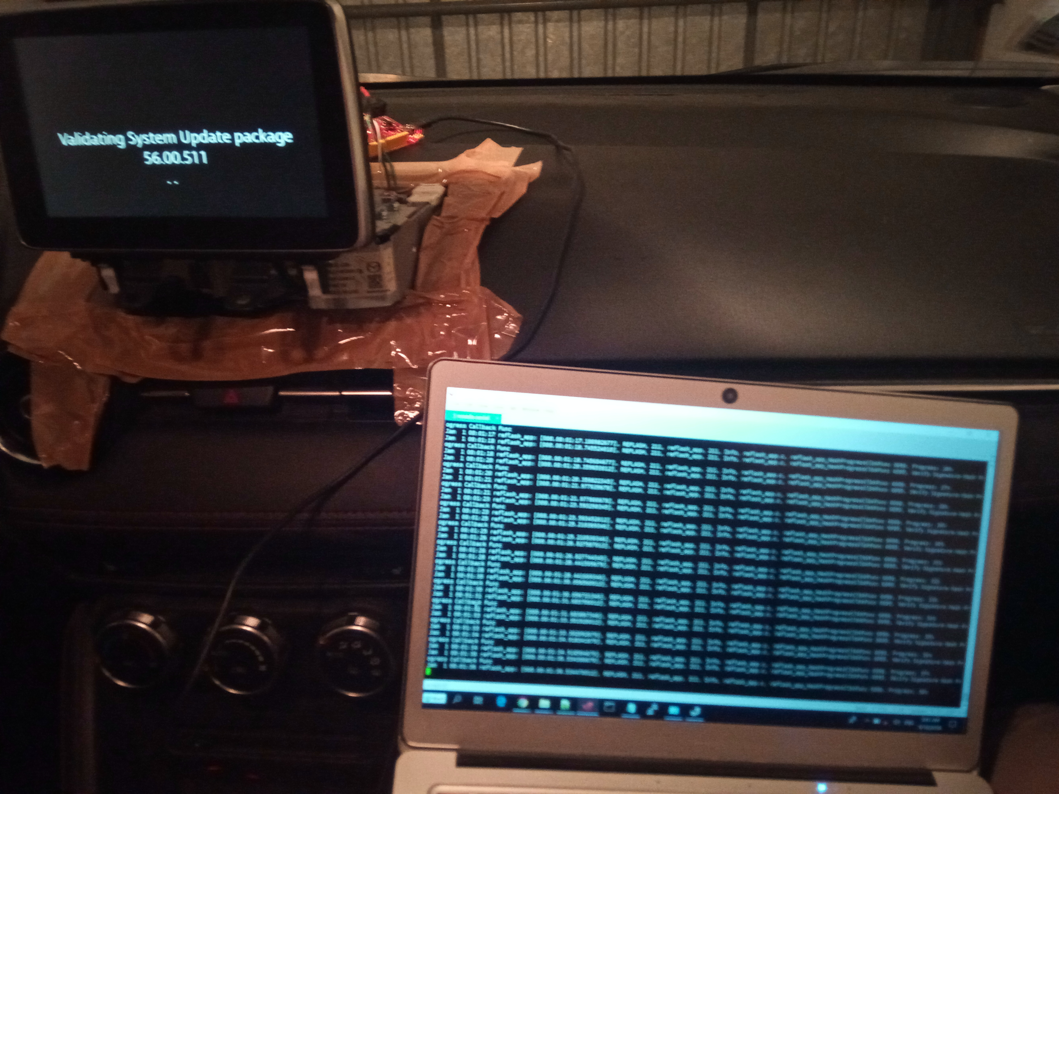
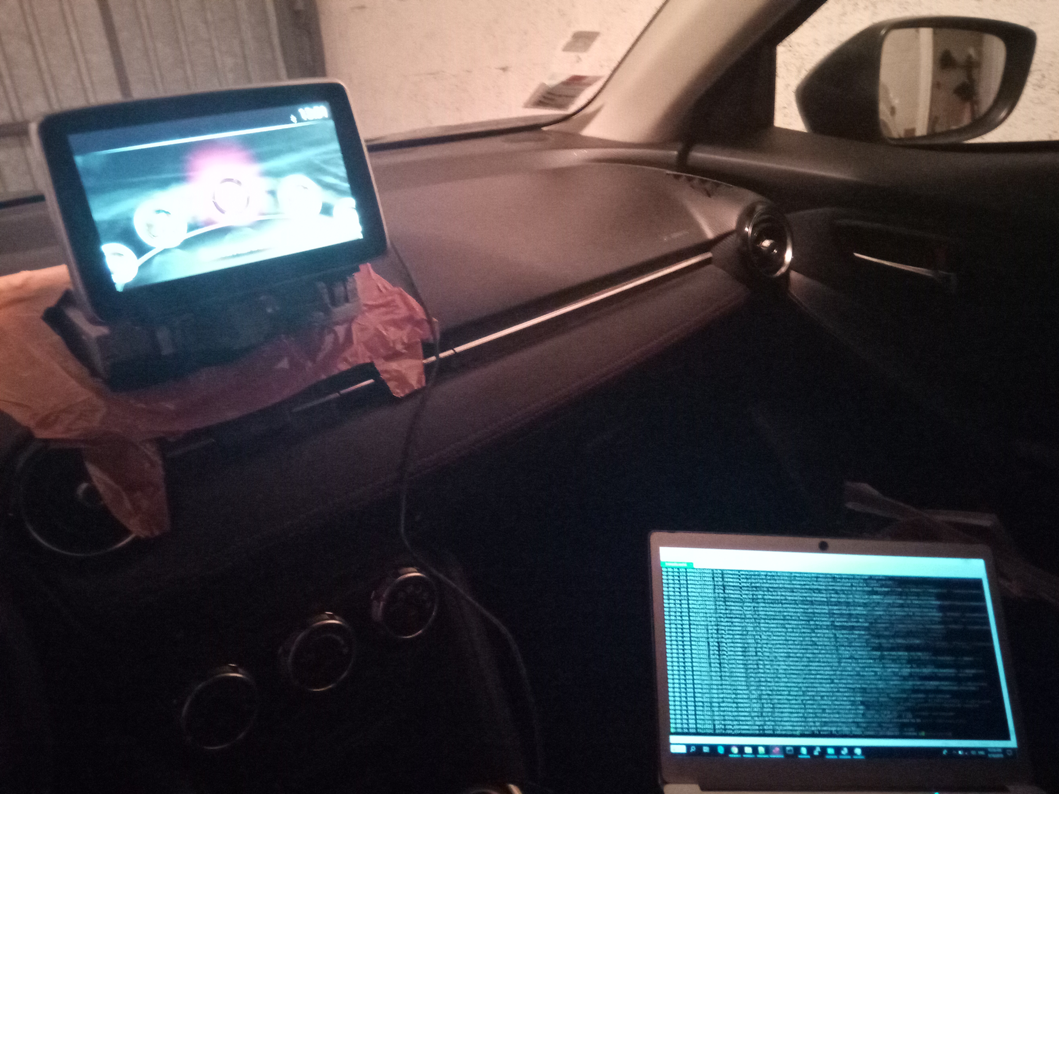
Après avoir injecté ce script par la procédure décrite plus haut, celle du chat raisonné, quel bonheur de voir le failsafe s’executer au prochain reboot, qui permet de réinstaller le firmware (les 2 fichiers up) placées judicieusement dans un clé usb branchée sur le système.
Et de voir la vie renaître sur cet écran:
Information intéressante finale numéro 1: ne pas oublier d’appuyer régulièrement sur la pédale d’embrayage, le voyant d’indicateur du bouton on/off de la voiture change d’état, et ça semble empêcher la mise en standby non souhaitable pendant le flashage du firmware
Information intéressante finale numéro 2: cette procédure semble pouvoir fonctionner dans tous les véhicules mazda un peu récents (>=2014), mazda 2, 3, 6, cx-5… et le user par défaut est user (avec droits root), le mot de passe jci
A l’occasion d’une légère modification de ma sonnette (basique, sinon les quelques sonneries proposées, qu’on ne peut mettre à jour dixit le mode d’emploi) pour l’alimenter en USB (plutôt que les piles AA d’origine vite vidées), quelle fût ma surprise en voyant que le PCB fourmille de possibilités:
emplacement 2 pins avec label « MOTOR »
emplacement pour bouton pressoir afin de changer de « mode »
emplacement pour port USB… pour mettre à jour les sonneries pour une hypothétique version plus avancée, ou mieux une connection série (pour la brancher sur un arduino/raspberry.. pour être notifié de l’activation de la sonnette par sms via e.g. l’API smsapi.free-mobile.fr.. plein de possibilités!)
Petit article coup-de-gueule : ou comment vouloir faire trop d’économies peut coûter cher!
Un adaptateur USB 220V/5V, c’est toujours pratique pour alimenter un arduino ou autre montage pour lequel une batterie n’est pas pratique (consommation trop importante, flemme de maintenir une batterie bien chargée..).
Fin 2014, je commande donc 5x adaptateurs, et tant qu’à faire les moins chers de l’un des sites sur lesquels j’ai l’habitude de commander. A l’époque, 12.05 € les 5, soit 2.41 € l’unité. Soit 2 pains au chocolat – ou 20, selon les sources ;).
Au moment ou ces lignes sont écrites (un peu plus de deux ans après l’achat mentionné), le court du chargeur low-cost a un peu monté, 3.12 € désormais. L’apparence extérieure n’a pas changé. J’espère que l’intérieur, lui, a changé. Mais pourquoi donc, oui, mais pourquoi?
L’extérieur
La première chose qui frappe, c’est le poids de la chose. C’est très léger.
Et déshabillé, ça donne:
Et enfin, comparé à un chargeur fourni avec un téléphone relativement récent (moto X v2 de 2014):
Bon, très bien, c’est à la mode d’être léger… vraiment?
Ouvrons lui ses tripes
Avec une partie des sous-titres:
On a les 220V branché quasi-direct sur le condensateur de 400V/2.2uF (), par l’intermédiaire d’une résistance et d’une diode.
Le C945 P331 est un transistor (voir les specs ici), c’est à dire un interrupteur. On remarquera que la saturation max en courant sur le collecteur est donnée à 300mA. Pas énorme, surtout quand on se rappelle que l’USB 1/2 doit pouvoir faire passer du 500mA.
A l’occasion d’un article future, nous pourrons essayer de déterminer les valeurs théoriques du condensateur d’entrée et de filtrage (16V/20uF), pour les comparer aux valeurs employées ici. Qui sait, peut être pourrait-on être surpris?
Il y a quoi derrière?
Aie!
Comme on peut le voir, on en peut pas dire que basses (5V) et hautes (220V) tensions soient séparées ici.. Mais surtout, les lignes phase et neutre sont séparées de moins d’un millimètre !! Une invitation aux arcs électriques, avec joyeusetés qui s’ensuivent (incendies, électrisation ou pire..). Surveiller son taux d’humidité devient alors vital.
Conclusion
Pour la petite histoire, le premier de ces adaptateurs que j’ai tenté de brancher au secteur, sans charge aucune, a provoqué un effet sonore inattendu, un grand boom.
Ce qui participé au repos des ses 4 camarades, jusqu’au dépecage pour cet article.
Je tiens tout de même à signaler que la boutique m’a remboursé l’intégralité des 12.05 € de cette commande. Je n’en n’ai pas recommandé pour constater l’évolution..
Si j’avais eu le cran de tester les autres adaptateurs, ou si ce moment arrive, alors il aurait été plaisant de vérifier la tenue en tension en montant la charge (le courant demandé).
Ah, chose intriguante, le pétard a bien l’inscription CE. Rassurant?